Supervision Exists Everywhere: A Data Efficient Contrastive Language-Image Pre-training Paradigm
Recently, large-scale Contrastive Language-Image Pre-training (CLIP) has attracted unprecedented attention for its impressive zero-shot recognition ability and excellent transferability to downstream tasks. However, CLIP is quite data-hungry and requires 4
arxiv.org
0. Abstract
최근, CLIP 모델이 강력한 zero-shot 능력과 downstream task에 대한 훌륭한 전이성으로 관심을 끌어왔다. 그러나 CLIP은 상당히 많은 데이터를 필요로 하며, 사전 학습을 위해 4억 개의 (이미지-텍스트) 쌍을 요구하기 때문에 이를 채택하는 데 제약이 있다.
본 연구에서는 이러한 제약을 완화시킨 새로운 학습 패러다임인 DeCLIP(Data efficient CLIP)을 제안한다. 이미지-텍스트 쌍의 지도 학습 방법들을 활용함으로써, DeCLIP은 더 효과적으로 시각적 특징을 학습할 수 있다.
단일 이미지-텍스트 contrastive supervision을 사용하는 대신, 다음과 같은 방법들을 통해 데이터의 잠재력을 최대한 활용한다.
1. 각 modality 내에서의 self-supervision
2. modality 간 multi-view supervision
3. 다른 유사한 쌍으로부터의 nearest-neighbor supervision
DeCLIP-ResNet50 모델은 ImageNet zero-shot top-1 accuracy에서 CLIP-ResNet50보다 훨씬 적은 데이터를 사용함에도 더 높은 성능을 보였다. 또한 downstream task에 전이 될 때 11개의 데이터셋 중 8개에서 기존 CLIP을 능가한다.
1. Introduction
지난 몇 년 간 pre-trained 모델은 computer vision과 NLP에서 큰 발전을 이끌어왔다.
anguage-image pre-training은 매우 큰 규모로 확장될 수 있으며 인터넷 상의 충분한 이미지-텍스트 쌍을 활용함으로써 이득을 얻을 수 있다. CLIP과 ALIGN과 같은 모델은 4억 개에서 10억 개의 이미지-텍스트 쌍을 포함한 데이터셋으로부터 학습하여 뛰어난 성능을 달성한다.
그러나 이러한 방법들은 많은 저장 공간과 컴퓨팅 자원을 요구한다.
본 연구에서는 이러한 이전 연구들이 단일 이미지-텍스트 contrastive supervision만 사용하고 쌍 내의 보편적인 supervision을 간과하여 효율적이지 않다고 주장한다.
1. 각 modality 내에는 풍부한 구조적 정보가 내재되어 있다. (self-supervision)
- 문장이나 이미지에서 일부 단어나 픽셀을 조정하면서도 비슷한 의미를 유지할 수 있는데, 이러한 self-supervision은 각 modality에 대해 보다 일반적인 표현을 학습하는 데 활용될 수 있다.
2. multi-view supervision을 multi-modality 설정에 확장한다.
- 각 이미지는 augmentation을 통해 얻어진 다양한 텍스트 설명과 쌍을 이루도록 하며, 그 반대도 마찬가지이다. 이는 더 많은 불변적이고 robust한 정보를 가져온다.
3. 다른 유사한 쌍으로부터의 NN(nearest-neighbor) supervision을 제안한다.
이는 하나의 이미지가 데이터셋 내에서 다른 유사한 텍스트 설명을 가질 가능성이 높다는 직관에 기반한다.

이에 embdding space에서 NN을 샘플링하고 추가적인 supervisory 신호로 활용한다.
이러한 supervision을 집계하여 새로운 학습 패러다임 DeCLIP을 구성한다.
downstream task에 전이될 때 DeCLIP-ResNet50 모델이 CLIP-ResNet50 모델을 11개의 데이터셋 중 8개에서 능가하고, 모델을 확장하고 컴퓨팅을 적용하는 것도 잘 작동한다.

본 연구의 기여는 다음과 같다.
- 몇 백만 규모의 이미지-텍스트 pretrainng task에서 self-supervision과 cross-modal multi-view supervision을 처음으로 연구하였다.
- 새로운 cross-modal Nearest-Neighbor Supervision(NNS)를 제안하였으며, 이는 semantic-level augmentation으로 간주될 수 있다.
2. Related Work
2.1. Pre-Trained Models
pre-training의 중요한 아이디어는 대규모 데이터에서 내포된 일반적인 지식을 추출하고 이를 다양한 downstream task에 전이하는 것이다.
DeCLIP은 인터넷 상에서 풍부하게 제공되는 이미지-텍스트 쌍에서 직접 학습하며, 쌍 내의 보편적인 supervision 방법을 활용하여 이전 기술보다 데이터를 효율적으로 활용한다.
2.2. Supervision Within Data
- Language supervision
CLIP과 ALIGN은 4억 개에서 10억 개의 이미지-텍스트 쌍을 학습하여 뛰어난 성능을 달성하였다. 본 연구에서는 이 두 연구를 바탕으로 데이터 효율성을 개선하기 위해 노력한다.
- Visual self-supervision
본 연구는 self-supervised learning(SSL)과 매우 관련이 있다. SSL의 선행 task로서의 contrastive learning은 시각적 representation 학습에서 큰 성과를 얻었고, 이를 multi-modal 환경으로 확장하기도 했으나 작은 COCO dataset에만 한정되었다.
- Nearest-neighbor supervision
최근 연구자들은 nearest-neighbor supervision을 시각적 특성을 학습하는 데에 확장하였다. contrastive loss에서 positive sample로 nearest-neighbor를 사용하는 것이 다수의 downstream task에서 성능을 향상시킴을 발견했다.
그러나 단일 시각적 modality pretraining에 중점을 두었으며, 본 연구에서는 multi-modal learning을 위한 방법을 제안한다.
2.3. Multi-Modal Learning
대부분의 vision-language 모델은 텍스트와 이미지 간의 정보를 융합하고 align하기 위해 여러 개의 cross-modal transformer를 사용한다. 이러한 방법들은 보통 object detector를 사용하여 영역 특징을 추출하거나 전용 cross-modal transformer layer를 필요로 하는데, 이는 확장 가능성을 저해한다.
DeCLIP은 단순하면서도 효과적인 two-tower 프레임워크를 사용하며, multi-modal 상호작용은 최상단에서만 이루어진다.
3. Approach
3.1. Revisiting CLIP
CLIP(Contrastive Language-Image Pre-training)은 이미지에 대한 raw 텍스트를 직접적으로 학습하는 것을 목표로 한다.
모델은 image encoder, text encoder를 가지고 있으며 최상단에 multimodal 상호작용이 있다. 이미지와 텍스트 feature는 같은 차원으로 투영되고 L2 정규화를 거친다.
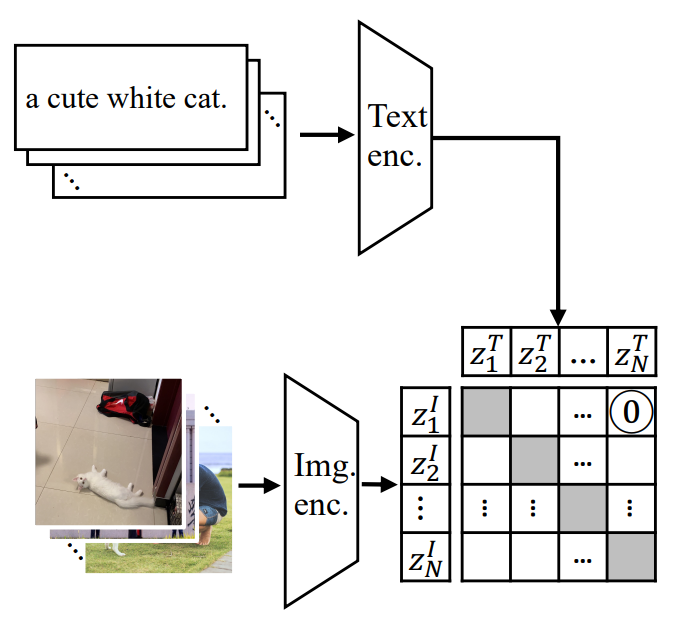
학습 단계에서, contrastive objective는 매칭 이미지-텍스트 쌍의 embedding은 가까워지고, 매칭이 아닌 이미지-텍스트 쌍의 embdding은 멀어지도록 한다.
CLIP은 InfoNCE loss를 사용하며, image encoder를 위한 loss는 다음과 같다.
$x_i^I$, $x_i^T$: i번째 이미지, 텍스트 쌍
$z_i^I$ : i번째 이미지의 정규화된 embedding
$z_j^T$: j번째 텍스트의 정규화된 embedding

유사도 함수 sim(,)은 dot product에 의해 측정되고, $\tau$는 logits을 스케일링 하기 위한 학습 가능한 변수이다.
image와 text encoder에 대해 대칭적인 loss를 사용하기 때문에, 전체 loss function인 $L_{CLIP}$은 $L_I$와 $L_T$의 평균이다.
테스트 단계에서, 학습된 text encoder는 테스트 데이터셋의 임의의 category를 embedding함으로써 zero-shot linear classifier를 합성한다.
본 연구에서는 CLIP과 같은 prompt engineering과 ensemble 기법을 사용한다.
3.2. Overview Of DeCLIP
DeCLIP은 3개의 추가적인 supervisory 신호가 있다.

1. Self-Supervision (SS)
- image SS
SimSiam 방법론을 채택하여, 이미지로부터 augmentation을 두 번 적용하여 두 feature 간 유사도를 최대화한다.
- text SS
Masked Language Modeling(MLM)을 적용한다.
2. Cross-modal Multi-View Supervision(MVS)
이미지와 텍스트에 대해 확률적 data augmentation을 적용하고, 각 example에 대해 두개의 view를 얻는다.
그러면, 이미지-텍스트 contrastive loss는 2 x 2 pairs에 대해 계산된다.
3. Nearest-Neighbor Supervision (NNS)
embedding 공간에서 얻은 NNS를 사용하여 데이터셋 사이에 비슷한 텍스트 설명의 사용을 더 잘 활용하도록 한다.
전체 데이터 분포를 대표할 수 있는 선입선출 큐를 유지하고, embedding space에서 nearest-neighbor을 사용해 의미적으로 유사한 텍스트 설명을 얻는다. 그 다음 이미지-텍스트 contrastive loss를 사용하여 supervision을 제공한다.
3.3. Supervision Exists Everywhere
- Self-Supervision within each modality
SimSiam 방법론에 따르면, 각 이미지에 대해 두 개의 augmented view를 얻고, 이 두 view는 image encoder로 전달된다.
2-layer MLP로 구성된 비선형 predictor module을 사용하여 encoder에서 representation quality를 향상시킨다.

목표는 $\tilde{z}^I$와 $p^I$ 사이의 유사도를 최대화, 즉 negative cosine similarity를 최소화한다. 또한 학습의 안전성을 위해 Stop-grad 기법을 사용한다.
텍스트 self-superision을 위해 BERT에서의 방법론을 따른다.

각 sequence에서 모든 토큰의 15%를 랜덤으로 선택한 후, 80% 확률로 [mask] 토큰으로 대체, 10% 확률로 랜덤한 토큰으로 대체, 10% 확률로 변경하지 않고 그대로 남긴다. 그 다음 해당 토큰에 대한 언어 모듈의 출력을 사용하여 원래의 토큰을 예측하고, 이 과정에서 cross-entropy loss를 사용한다.
- Multi-View Supervision
이미지의 텍스트 주석은 전체 이미지를 설명하는 것이 아닐 수 있으며, 이미지의 작은 local view를 묘사할 수 있다. 이를 극복하기 위해 이미지의 local region을 더 자세히 살피고 이를 보조 supervision으로 활용한다(Multi-crop과 유사한 방식).
이것을 multi-modal setting으로 확장하는데, SS에서 소개된 두 개의 이미지 view를 재사용한다.
텍스트의 경우 문장의 전체 의미를 이해하는 것이 목표이므로, 텍스트 분류 augmentation인 EDA를 사용하여 두 개의 텍스트 view를 사용한다.
$(z_I, z_T)$ 사이의 원래 대조 손실 외에도, $(z_I, \tilde{z}_T)$, $(\tilde{z}_I, z_T)$, $(\tilde{z}_I, \tilde{z}_T)$를 대조하여 3배의 다양하고 고품질의 추가 supervision을 제공할 수 있다.
- Nearest-Neighbor Supervision
한 이미지는 데이터셋에서 다른 비슷한 텍스트 설명을 가질 수 있기 때문에, 다양한 supervision을 얻기 위해 NN을 사용할 것을 제안한다.
embedding spae에서 텍스트 feature $z_T$와 유사한 $z^{T’}$을 찾는 것을 목표로 한다.

두 feature 사이의 거리는 간단한 코사인 유사도로 측정될 수 있다.
백만 개 규모의 데이터셋에서 NN을 검색하는 것을 현실적으로 불가능하기 때문에, 전체 데이터 분포를 시뮬레이션하기 위해 FIFO 큐를 유지한다.
$(z^I, z^{T'})$ 사이의 contrastive loss를 추가적으로 얻을 수 있으며 두개의 augmented 이미지 feature가 있기 때문에, $(\tilde{z}^I, z^{T'})$ 사이의 contrastive loss도 계산할 수 있다.
이러한 방법론들을 추가한 DeCLIP의 전체 loss function은 다음과 같다.

4. Experiments
4.1. Datasets
- Pretraining datasets
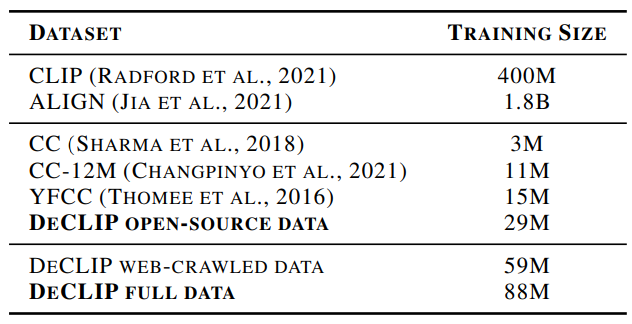
DeCLIP의 데이터는 open-source 데이터와 web-crawled 데이터 두 가지로 구성되어 있다.
open-source data(CC3M, CC12, YFCC)에 대해서는 다운로드 실패 또는 영어 caption이 없기 때문에, 완전한 데이터를 얻지 못했다.
- Downstream datasets
CLIP과 마찬가지로, image encoder 전이성을 11개의 downstream 데이터셋에 대해 평가한다.
4.2. Experiments Setup
- Network architectures
CLIP을 따라 image encoder는 ResNet50과 ViT, text encoder는 Transformer의 수정된 버전을 사용한다.
이미지와 텍스트 feature는 1024차원으로 투영되고, L2 정규화를 적용한 후 상호작용한다.
- Pre-training setup
CLIP과의 비교를 위해, DeCLIP-ResNet50과 DeCLIP-ViT-B/32를 처음부터 32 epoch 훈련 시킨다.
- Downstream evaluation setup
모델 전이성을 평가하기 위해, feature를 고정시킨 후 linear classification을 수행한다.
즉 pre-trained image encoder는 고정되어 feature extractor로 사용되고, linear classifier를 훈련시킨다.
4.3. Main Results
- Zero-shot recognition on ImageNet
pre-training 이후, 자연어를 사용하여 시각적 개념을 참조함으로써 zero-shot 능력을 가능하게 한다.
DeCLIP-ResNet50은 CLIP-ResNet50을 모든 데이터셋 사이즈에서 능가한다.

데이터 양이 56M일 때 accuracy 60.4%를 달성하는데, 이는 CLIP-ResNet50보다 7.1배 적은 데이터를 사용했음에도 0.8% 높은 수치이다.

DeCLIP-ResNet50은 CLIP-ResNet101보다도 0.3% 더 나은 성능을 보여주어, DeCLIP의 프레임워크가 효과적이고 효율적임을 나타낸다.
- Downstream evaluation results
11개의 downstream 데이터셋에 대해 linear probe 성능을 측정했다.
DeCLIP-ResNet50 모델이 11개 중 8개에서 CLIP을 능가했으며, 평균적으로 0.8%의 성능 개선이 있었다.

CLIP 모델에 비해 성능이 안 좋은 데이터셋도 있었는데, 이는 pre-trained 데이터셋의 분포와 다르기 때문이라고 추측한다.
4.4. Ablation Study
- Ablation on additional supervision
각 supervision의 효과를 확인하기 위해 ablation study를 한 결과이다.

ImageNet에서 기존 CLIP 모델은 zero-shot top1 accuracy가 20.6%였으며, MVS가 4.2%의 성능을 올렸다.
SS는 MVS 적용 결과를 기준으로 0.6%의 추가 성능 개선에 기여했고, NNS는 SS를 기준으로 1.8%의 성능 개선에 기여했다.
- Ablation on training cost
각 이미지-텍스트 쌍에 대해 두번 encoding해야 하기 때문에, DeCLIP이 CLIP보다 더 높은 학습 비용이 필요하다.
그러나 DeCLIP은 높은 정확도를 기록하며, 동일한 시간 학습시킨 CLIP보다 5.3% 더 높다.

4.5. Analysis
- Class activation maps
DeCLIP이 효과적인 이유를 이해하기 위해, 다양한 모델의 CAM을 시각화했다.

CLIP 모델이 object의 작은 부분만 보는 반면, DeCLIP 모델은 완전한 object를 segment한다.
- Nearest neighbor samples
다양한 데이터셋으로부터 NN samples를 추출한 결과이다.

원래의 쌍과 NN의 쌍이 비슷하기 때문에, NN pair가 높은 퀄리티의 supervision을 제공할 수 있다는 것을 알 수 있다.
5. Conclusion
본 연구의 목표는 더 넓고 확장 가능한 supervision을 통해 시각적 representation을 학습하는 것이다.
단일 이미지-텍스트 contrastive supervisoin 대신에, ① 각 modality 내에서의 self-supervision ② multi-view supervision ③ 다른 비슷한 쌍으로부터의 nearest-neighbor supervison을 사용하여 데이터의 잠재력을 활용한다.
실험적으로, 다양한 유형의 신경망(CNN과 ViT)과 다양한 데이터 양에서 우수한 효과성과 효율성을 보여준다.



